Functions
Lookup
VLOOKUP
How to Use Excel's VLOOKUP Function in Pandas
Excel's VLOOKUP function is a versatile tool for searching and matching data across columns. The VLOOKUP and XLOOKUP functions are often interchangeable, however, VLOOKUP tends to be more popular because it's been around longer.
This page explains how to replicate Excel's VLOOKUP functionality in Python using pandas.
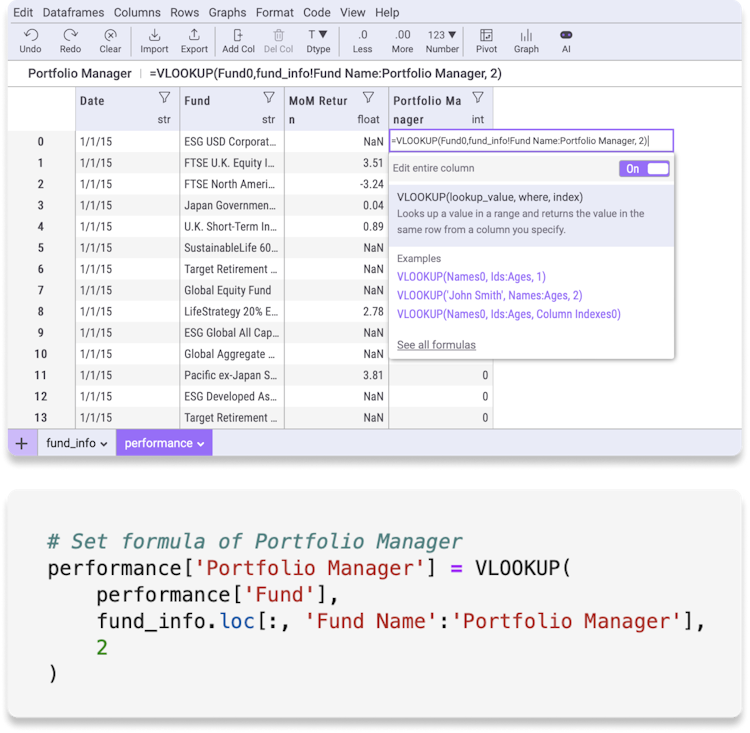
Use Mito's VLOOKUP function
Mito is an open source library that lets you write Excel formulas in Python. Either write the formula directly in Python or use the VLOOKUP formula in the Mito Spreadsheet and generate the equivalent Python code automatically.
Mito's VLOOKUP function works exactly like it does in Excel. That means you don't need worry about managing data types, handling errors, or the edge case differences between Excel and Python formulas.
Install Mito to start using Excel formulas in Python.
# Import the mitosheet Excel functions
from mitosheet.public.v3 import *;
# Use Mito's VLOOKUP function
# Note: Mito's VLOOKUP formula automatically performs a
# case-insensitive lookup, just like Excel
df1['returned_value'] = VLOOKUP(df1['A'],df2.loc[:, 'A':'B'], 2)
Implementing the VLOOKUP and XLOOKUP function in Pandas#
To replicate the VLOOKUP or XLOOKUP function in Excel using Python and pandas, you can use the `merge` method combined with other functions. Here's a common use case:
Join dataframes together using a single condition#
In Excel, you would use the VLOOKUP function to add data from one table into another, based on a matching value.
In pandas, the equivalent functionality can be achieved using the `merge` method. Below is an exampls of how you can use the `merge` function to find matching values between two tables and return additional data from the second table.
Because the VLOOKUP function is case-insensitive, before merging the data together in pandas, convert the columns to lowercase so that you'll have the same results in Excel and Python.
grades = pd.DataFrame({
'Name': ['aaron sand', 'martha wax', 'nate joy', 'jake jones'],
'Math': [88, 100, 89, 92],
'English': [92, 91, 90, 94],
'History': [95, 92, 91, 90],
'Science': [89, 88, 90, 87],
'Gym': [90, 92, 91, 90],
'Art': [91, 90, 94, 92]
})
student_records = pd.DataFrame({
'Name': ['Martha Wax', 'Nate Joy', 'Aaron Sand'],
'Year': [2016, 2016, 2016],
})
# Convert the Name columns to lowercase for case insensitive merge
grades['Name'] = grades['Name'].str.lower()
student_records['Name'] = student_records['Name'].str.lower()
# Drop Gym and Art columns from the grades DataFrame so they're not included in the final
# final student_record. Create a temporary df so we don't modify the original dataframe.
tmp_grades = grades.drop(['Gym', 'Art'], axis=1)
# Drop duplicates from grades on the Name column to ensure we only
# return one result per student
tmp_grades = tmp_grades.drop_duplicates(subset=['Name'])
# Add the columns Math, English, History, and Science to the student_records DataFrame
student_records = student_records.merge(tmp_grades, left_on='Name', right_on='Name')Merge dataframes using mulitple conditions (merge keys)#
Sometimes it's not enough to match based on a single column. For example, in the previous example if instead of having a Name column, you had a First Name and Last Name column, you'd want to use both columns to match the data.
In Excel you might use a helper column to combine the two columns into a single column, then use VLOOKUP to match on that column. Alternativly, you could use XLLKUP to match on multiple columns with the formula: =XLOOKUP(1, (Sheet2!A:A=A1)*(Sheet2!B:B=B1), Sheet2!C:C, "Not found", 0, 1)
In pandas, you can perform a multiple condition lookup by passing a list of columns to the `on` parameter in the `merge` function.
grades = pd.DataFrame({
'First Name': ['aaron', 'martha', 'nate', 'jake'],
'Last Name': ['sand', 'wax', 'joy', 'jones'],
'Math': [88, 100, 89, 92],
'English': [92, 91, 90, 94],
'History': [95, 92, 91, 90],
'Science': [89, 88, 90, 87],
'Gym': [90, 92, 91, 90],
'Art': [91, 90, 94, 92]
})
student_records = pd.DataFrame({
'First Name': ['Martha', 'Nate', 'Aaron'],
'Last Name': ['Wax', 'Joy', 'Sand'],
'Year': [2016, 2016, 2016],
})
# Convert the First Name and Last Name columns to lowercase for case insensitive merge
grades['First Name'] = grades['First Name'].str.lower()
grades['Last Name'] = grades['Last Name'].str.lower()
student_records['First Name'] = student_records['First Name'].str.lower()
student_records['Last Name'] = student_records['Last Name'].str.lower()
# Drop Gym and Art columns from the grades DataFrame so they're not included in the final
# final student_record. Create a temporary df so we don't modify the original dataframe.
tmp_grades = grades.drop(['Gym', 'Art'], axis=1)
# Drop duplicates on the First Name and Last Name columns to ensure
# we only return one result per student
tmp_grades = tmp_grades.drop_duplicates(subset=['First Name', 'Last Name'])
# Add the columns Math, English, History, and Science to the student_records DataFrame
student_records = student_records.merge(
tmp_grades,
left_on=['First Name', 'Last Name'],
right_on=['First Name', 'Last Name']
)Fuzzy Match Vlookup to combine dataframes using approximate matches#
In some cases, you may not have an exact match for your VLOOKUP key. In this case, fuzzy matching can be useful. Fuzzy matching is a technique that finds approximate matches for records. For example, if the names in our grades table contained nicknames or misspellings, we could use fuzzy matching to match A-A-Ron to Aaron.
Just like there isn't native fuzzy matching in Excel, in order to perform fuzzy matching in pandas, you'll need to use a third party library like fuzzywuzzy or thefuzz.
from fuzzywuzzy import process
grades = pd.DataFrame({
'Name': ['a-a-ron sand', 'martha wax', 'nathan joy', 'jacob jones'],
'Math': [88, 100, 89, 92],
'English': [92, 91, 90, 94],
'History': [95, 92, 91, 90],
'Science': [89, 88, 90, 87],
'Gym': [90, 92, 91, 90],
'Art': [91, 90, 94, 92]
})
student_records = pd.DataFrame({
'Name': ['Martha Wax', 'Nate Joy', 'Aaron Sand'],
'Year': [2016, 2016, 2016],
})
# For each Name in student_records, find the best match in grades
student_records['best_match'] = student_records['Name'].apply(lambda x: process.extractOne(x, grades['Name'].tolist()))
student_records['best_match'] = student_records['best_match'].apply(lambda x: x[0])
# Drop Gym and Art columns from the grades DataFrame so they're not included in the final
# final student_record. Create a tmp_df so we don't modify the original dataframe.
tmp_grades = grades.drop(['Gym', 'Art'], axis=1)
# Drop duplicates from grades on the Name column to ensure we only
# return one result per student_record
tmp_grades = tmp_grades.drop_duplicates(subset=['Name'])
# Add the columns Math, English, History, and Science to student_records merging on the best match
student_records = student_records.merge(tmp_grades, left_on='best_match', right_on='Name')
# Drop the best_match and Name_y column because we no longer need them
student_records = student_records.drop(['best_match', 'Name_y'], axis=1)
# Rename the Name_x column to Name
student_records = student_records.rename(columns={'Name_x': 'Name'})Common mistakes when using VLOOKUP in Python#
The sneakiest and most common issues when trying to recreate Excel's VLOOKUP function in Python is differences in how Excel and Python handle case sensitivity and duplicate values.
Case Sensitivity#
By default, pandas' lookup functions are case-sensitive, whereas Excel's are case-insensitive. This can lead to missed matches in pandas.
To address this, you can convert both the dataframe column and the lookup value to the same case (either upper or lower) before performing the lookup.
# Convert to lowercase before lookup
df1['key'] = df['key'].str.lower()
df2['key'] = df['key'].str.lower()
result = df1.merge(df2, on='key', how='left')Forgetting to deduplicate the your data#
Excel's VLOOKUP function only returns the first match it finds. For example, if you are looking up the with 'Mito' in a table that contains two rows with 'Mito', Excel will return the first row.
The pandas merge function, on the other hand, will return one row for each match by default. That means, if you want to replicate Excel's VLOOKUP or XLOOKUP function, you need to deduplicate the dataframe you're looking up values in before performing the merge.
# Drop duplicates from grades column where the Name value is repeated.
# Keep the first row that contains a duplicate value
df = df.drop_duplicates(subset=['Name'])Using the wrong order of operations#
Because there are various steps that you need to take to replicate Excel's VLOOKUP function in pandas, it's easy to get the order of operations wrong. For example, if you deduplicate the dataframe that you are looking up values in before converting the values to lowercase, your merge is not gauranteed to return the same results as VLOOKUP. That's because the deduplication step itself is case-sensitive.
Figuring out the correct order can be confusing, but it's important to get right. If you're not sure, try to break the problem down into smaller steps and test each step individually.
Mismatched data types between the key columns#
The pandas merge function will throw a TypeError if the data types of the columns you're merging on don't match. For example, if you're merging on a column of strings, you'll need to convert the lookup value to a string before performing the merge.
# Convert the columns to a strings before merging
df1['key'] = df1['key'].astype(str)
df2['key'] = df2['key'].astype(str)
result = df1.merge(df2, on='key', how='left')Understanding the VLOOKUP and XLOOKUP Formula in Excel#
The VLOOKUP function in Excel searches a range for a key and returns the corresponding value from another range.
=VLOOKUP(lookup_value, table_array, col_index_num, [range_lookup])
VLOOKUP Excel Syntax
| Parameter | Description | Data Type |
|---|---|---|
| lookup_value | The value to search for | varies |
| table_array | The array or range containing the values to return | range |
| col_index_num | The column number in the table from which to retrieve the value. | number |
| range_lookup | (Optional) Set to 1 to find the closest match (default). Set to 0 to find an exact match. | boolean |
Examples
| Formula | Description | Result |
|---|---|---|
| =VLOOKUP("Mito", B1:C10, 2) | Search for the word "Mito" within B1:B10 and return the corresponding value from C1:C10. | Value from C1:C10 |
| =VLOOKUP("Mito", B1:C10, 2, FALSE) | Search for the word "Mito" within B1:B10 and return the corresponding value from C1:C10. Perform an exact match. | Value from C1:C10 |
Get answers from your data, not syntax errors. Download the Mito AI analyst
Don't want to re-implement Excel's functionality in Python?
Edit a spreadsheet.
Generate Python.
Mito is the easiest way to write Excel formulas in Python. Every edit you make in the Mito spreadsheet is automatically converted to Python code.
View all 100+ transformations →