





Turn data into insights and reports 4x faster with Mito AI
At Mito, our flagship feature is a chat interface powered by an LLM. When it works, it feels magical—automating everything from data cleaning to ML tasks. But when it fails, it's hard to tell whether the problem is isolated or systemic.
If you’re building on LLMs, you’ve likely been here: tweaking prompts without knowing if you're actually improving anything.
The Pitfall of Vanity Metrics
The obvious fix? Use evals. The problem? Our evals only returned vanity metrics.
Our first attempt was essentially unit tests: we paired user inputs with expected outputs, ran both, and checked for matches. While this gave us a pass rate, it didn’t tell us why something failed or how to improve. Eventually, we stopped using them.
A New Approach: Evals as Funnels
We revisited evals while tackling SQL generation. With many prompt variations to test, we needed a system that provided actionable insight—not just pass/fail stats.
Our solution: treat evals like a funnel, breaking them into stages to isolate failures and guide improvements.
Step 1: Test Groups
We organize prompts into categories like:
- Basic Retrieval
- Joins
- Aggregation
Step 2: Test Cases
Each test includes:
- A user prompt
- The expected SQL query
- The database schema
Step 3: Multiple Schemas
To measure performance, we created three schemas:
- Small: 1 database
- Medium: 5 databases
- Large: 10 databases, some overlapping in structure
Step 4: The Funnel
We run each LLM-generated query through a series of checks—even before execution:
- Was a query generated?
- Do tables exist in the schema?
- Any hallucinated tables?
- Any table-column mismatches?
- Can the query execute?
- Do column and row results match the expected?
Step 5: Results
All outcomes flow into a Streamlit dashboard, showing where things break and what to fix.
Actionable Evals
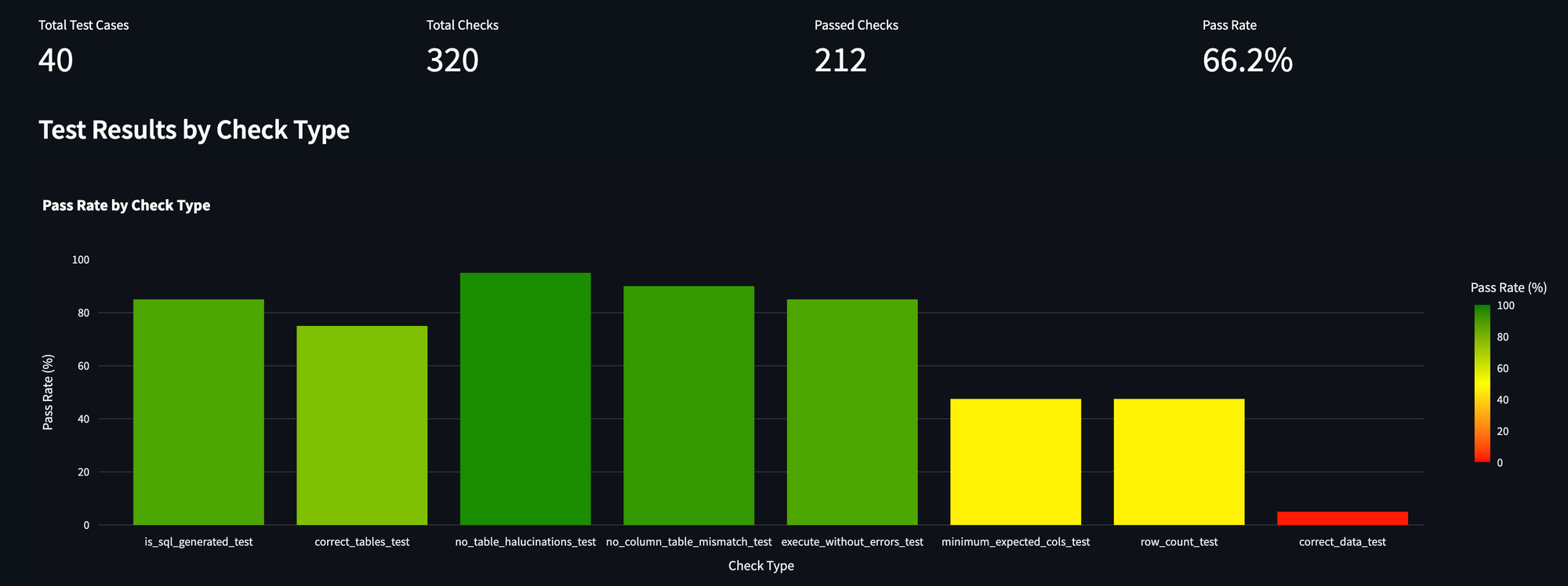
We still keep track of the overall pass rate, but now we can zoom in to the funnel. This allows us to see where performance starts to fall off.
In the chart above for example, we can see that there is not a lot of hallucination, but when we start to look at the actual results of the query there is a drop off (as seen by the yellow bars).
There is also a huge drop off at the end, but this final check is quite literal, looking for an exact match. Might make sense to remove this stage of the funnel. In most cases, it is possible for the AI to return more data than we are expecting, and still answer the user's question.
In fact, it may be entirely possible that additional data was selected because it contains features that the LLM believed would be relevant for developing a richer understanding of the problem.
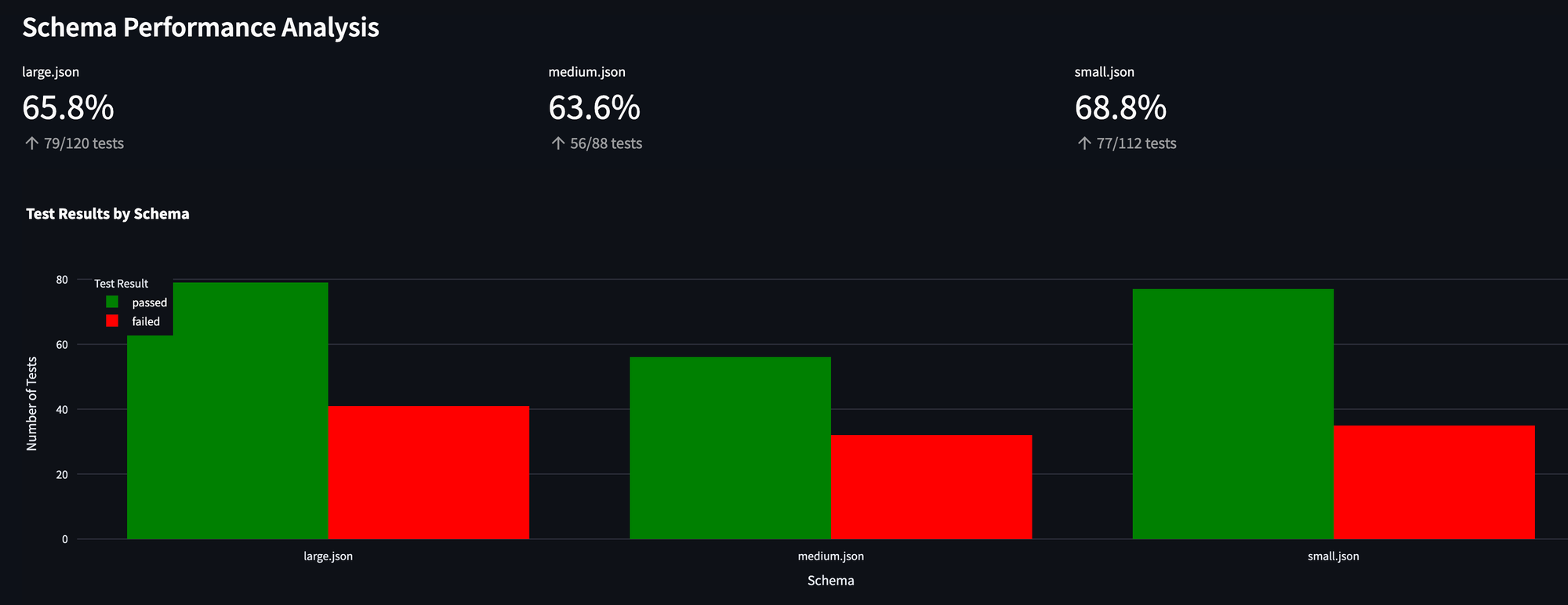
We were also able to benchmark schema performance, and see how different database sizes affect performance. One trick here (or perhaps laziness) is that we reused inputs from the small and medium test cases.
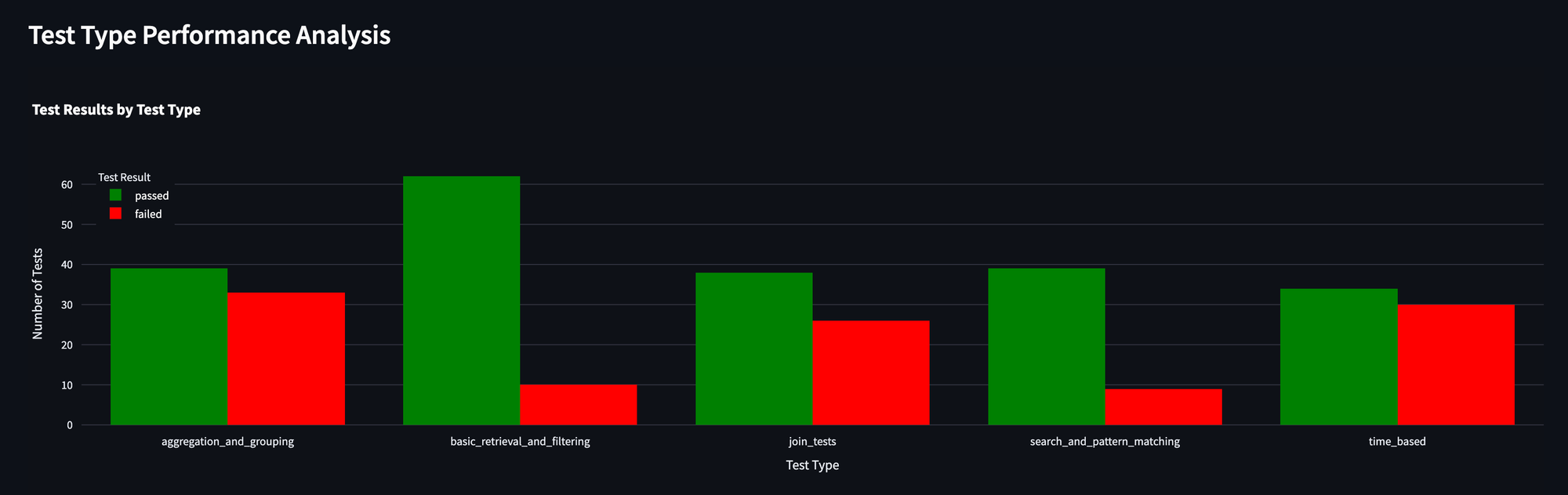
We also were able to zoom into different query types. This is super helpful for determining what parts of the prompt require more attention.
For example, time based queries have the slimmest margin, and are basically a tossup. We have a few theories on why this is happening.
First, our sample data is not up-to-date, so a request for the “last 5 days of stock prices” may use the current date, which does not exist in our database. To combat this we’ve included, in our prompts, “get the last n days of recorded data.” However, this may not be enough.
Additionally, it may be the case that queries dealing with datetime are just difficult, in which case we will probably spend some time manually prompting the LLM to determine where things are going awry.
However, this is the great thing about the funnel. Before we would spend our time testing whatever came to mind. Now we know that we should allocate some time on datetime queries.
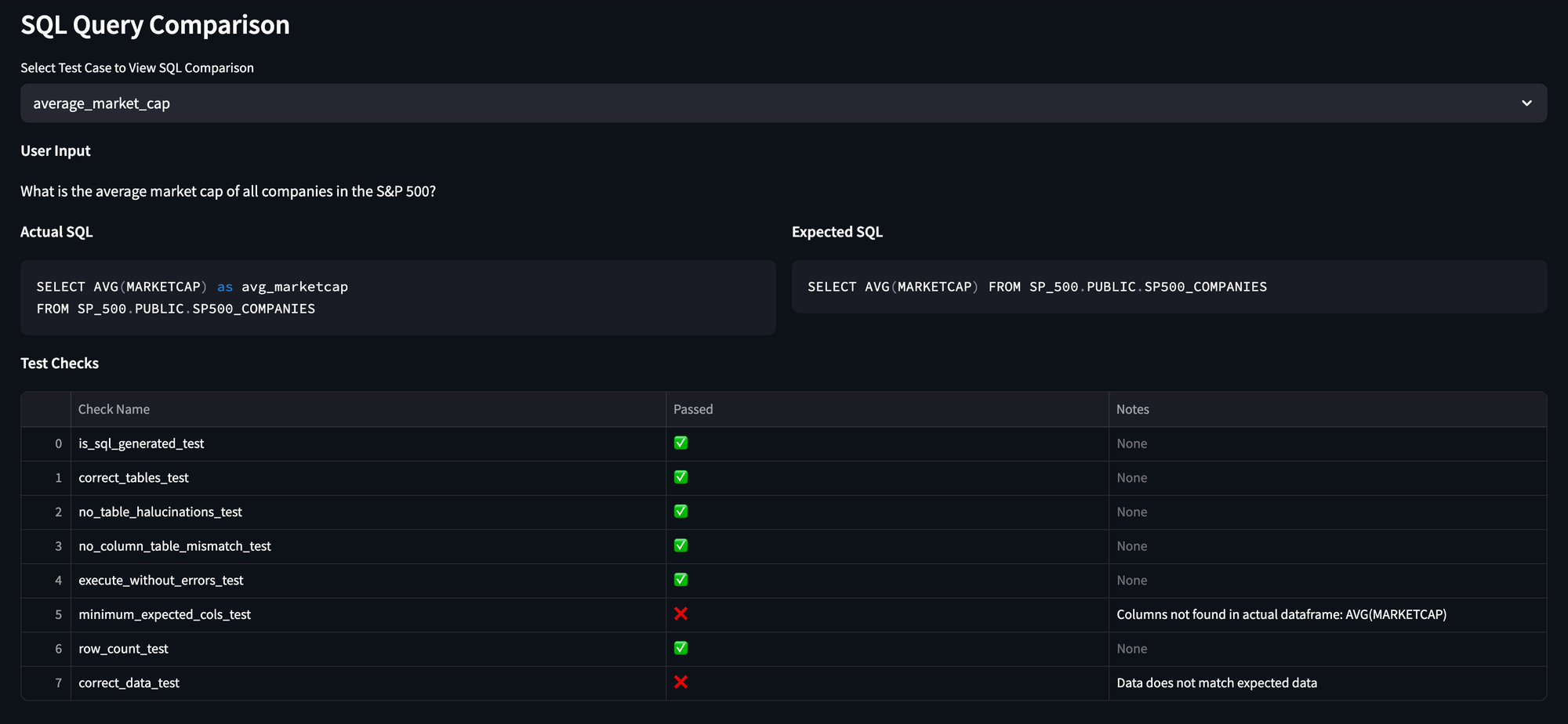
Finally, you have the ability to zoom into a specific test case, and see how it moved through the funnel.
Moving Forward
If you’d like to see how we implemented this funnel, you’re in luck our code is open source.
Our evals directory may be a bit overwhelming, because we’ve built an entire framework, but here are the highlights:
evals/test_runners/sql_test_runner.py- This is your main entry point. It collects the tests, creates the prompts, and runs the funnel.evals/prompts/chat_prompts/production_prompt_w_sql.py- This is our production prompt + sql rules.evals/funnels/sql/default.py- The actual funnel, which is just a series of steps.evals/funnels/sql/steps.py- The previous mentioned steps. Each step is essentially a test.
More Like This
Automating Spreadsheets with Python 101
How to tell the difference between a good and bad Python automation target.
10 Mistakes To Look Out For When Transitioning from Excel To Python
10 Common Mistakes for new programmers transitioning from Excel to Python
Research shows Mito speeds up by 400%
We're always on the hunt for tools that improve our efficiency at work. Tools that let us accomplish more with less time, money, and resources.
3 Rules for Choosing Between SQL and Python
Analysts at the world's top banks are automating their manual Excel work so they can spend less time creating baseline reports, and more time building new analyses that push the company forward.
Turn data into insights and reports 4x faster with Mito AI